2022-11-24
![]()
Back to Linux blog.
Better winesapOS Builds

winesapOS 3.2.0 is here with our most requested feature: a minimal image weighing in at only 7 GiB. Thanks to our amazing community, we get to work together to shape the future of Linux gaming.
With this grand new release, I wanted to take some time to reflect about how I have historically built my operating system and how I’m working on improving it. As a quick recap, winesapOS is a passion project of mine. It started off as a simple way for my best friend (who owns a Mac) to play Halo with me. The solution was straight forward, in theory: create a portable Linux operating system.
winesapOS has become a large project with a small cult following. To that end, I can count on one hand the number of contributors we have for our project. I’ve had to re-evaluate both the architecture and costs for server and build infrastructure. I’ve also switched to Starlink so there are some challenges that come with satellite internet. As they say, constraints are the gateway to ingenuity. How are we addressing these things?
-
Slimming down. We used to run our repository in a highly-available 3-node environment. However, we can tolerate downtime, the resource usage was small, and I could no longer justify the cost. Due to these reasons, we had to slim down to a single node. If demand ever became an issue, I would look into object storage or burst computing service offerings.
-
Reliable builds. We now force Pacman to use the “wget” command for all package downloads during the install process. This is great for slow or unreliable internet connections. The default Pacman behavior is to fail if a connection is too slow. This has helped me with my satellite internet and will help others in rural areas, too. This even extends beyond the builds. Release images now use “wget” as well so that everyone can benefit from this change.
-
Fast builds. I recently built out a Squid proxy server to help cache files. winesapOS now supports using proxies. My Squid proxy is setup to cache both HTTP and HTTPS content. For HTTPS, I essentially do a man-in-the-middle attack against myself. Don’t worry, for security and safety reasons, I don’t do this for release builds on GitHub. Don’t believe me? Check the full build debug log in your /etc/winesapos/winesapos-install.log file. With my proxy, I was able to get our secure image build down from almost 2 hours to 28 minutes! About 10 minutes of that is refreshing the Arch Linux keyrings (this is required to workaround issues if the Arch Linux ISO keyring is out-of-date). Essentially, our build is around 18 minutes now! This really helps when I may need to do multiple builds every night!
-
GitHub Actions. Thanks to my friend from the community @Thijzer, we now have automated testing! winesapOS was built from the ground-up to do test-driven development. This takes it a step further by testing every git commit via a GitHub Actions continous integration (CI) pipline. Long-term, I want to also include continuous delivery (CD) so that it can publish release images instead of me having to manually download them. This has saved a lot of time already and is paving the way for the future.
-
Reliable hardware from Intel. Intel graciously gifted me with a handful of Intel Optane drives to use. Not familiar with Intel Optane? These are data center grade drives that work wonders to remove I/O bottlenecks. I have many use-cases for them but I wanted to start off with winesapOS since I’m dealing with that on a daily basis. I ran a large amount of builds on these new drives and, ironically, the time to build the image was exactly the same: 28 minutes with a proxy. This clearly tells me that the bottleneck is not the drives but in my build script. It is very serial/linear. Moving forward, I will be focusing on parallelizing our build. I already have a few things in mind and we’ve already laid down some ground work to eventually support this. In the meantime, what benefit can these fancy Intel drives provide? If I were to keep using them as build drives, they would last a lifetime. Maybe even two or three lifetimes. Better yet, I intend on putting these drives to better use elsewhere such as my Squid proxy and/or ZFS file server. These would greatly benefit from the incredibly high IOPS.
-
Let me put the lifespan in perspective. Each asterik represents 5 years of use for building winesapOS (assuming I use 100 GB per day):
- * = My old NVMe drive.
- ** = Intel Optane 800P 120 GB.
- ****** = Intel Optane P1600X 120 GB.
- ************************************************ = Intel Optane 905P 480 GB. This is not a typo! The TBW lifespan on this drive is incredible. I’ve never seen a drive with such endurance!
-
Most Intel Optane drives are on sale right now for the holidays! Check out all of the various deals going on at NewEgg.
Have any other ideas for how we can improve winesapOS? Get in touch to let me know!
2023-05-01
![]()
Back to Linux blog.
Learn Rust in 30 Days

Introduction
Imagine a world full of peace and prosperity. A utopia of sorts. A place like Japan where you’ve never felt safer. A location where no security guards are required. This, my friends, is the world of the Rust programming language.
In all seriousness, Rust is a lot of fun to learn but comes with its own pros and cons like any language. For one thing, writing code takes longer and requires more lines than compared to Python. However, I believe the benefits outweight the negatives. More on that later. I’m here to share my personal experiences to help give you guidance. This is information I wish I had many years ago.
Why learn Rust specifically? It’s faster, more energy efficient, and more secure than C++. In a world where memory exploits (a non-issue in Rust) account for up to 90% of known vulnerabilities in Android, security matters big time. The kernels for both Linux and Windows are also starting to transition over to using Rust. Even graphics drivers are being made in Rust these days! This seems to be just the start of the next generation of programming.
Getting Started
Most people ask me where to even start when learning a programming language. I came up with my own guide that lists out the most important topics in the order they should be learned. This was a great starting point. As for how to learn Rust specifically? The first thing I did was collect a list of useful resources to study from here. Most folks will point you to “The [Rust] Book”, which is great. I have found that having a diverse set of study material is helpful.
30 days ago I started to learn Rust every day. There were a few “cheat days” where I didn’t do any programming but I made sure to always read up on new topics and start to understand some of the more complex subjects. As I once learned, it is better to study thirty minutes every day than one hour five days a week. If you can somehow tie this into work, it makes it even easier to do every day.
Try working on your own program from scratch. Here are some good beginner project ideas if you need some. At one point, I decieded to temporarily ignore the guides I was following and instead just work on a project to see what gaps there were in my knowledge. (Spoiler: there were a lot of gaps). So I decieded to work on my light show project: Make It Jingle (MIJ). This led me down a fun and very useful rabbit hole for a few days.
- Day 1: How do I install an external YAML library?
- Day 2: How do I read from a file?
- Day 3: How do I use a struct data type to define the layout of a YAML file?
- Day 4: How do I parse YAML?
End of an Era
At the end of 30 days, where was I at? Around 1,400 lines of notes consisting of 5,000 words. All of my Rust notes are open source here as part of my Root Pages project. I’ll always continue to update and add Rust notes there as long as I continue to use the language (which may be forever, who knows!).
$ wc src/programming/rust.rst
1391 5060 43061 src/programming/rust.rst
Where to Next?
Looking forward towards the future, these are my personal next steps. After 30 days, I feel this is the perfect opportunity to branch out away from textbooks and standard reading material. The journey isn’t over. In fact, it has just begun!
- Exercism = This is the best site to become an expert in any programming language. It is free and you are assigned human mentors to assess and review your code.
- uutils coreutils = Many projects, such as this one, have a “good first issue” label attached to bug and feature requests. I have a personal interest in this project as I want to use it for my operating system I built: winesapOS.
- Make It Jingle (MIJ) = This is a side project I started to write in Python. I was hoping to get speed advantages with the PyPy compiler but ran into a huge limitation: most of the libraries I needed are not supported. In comparison, Rust is just inherently faster since it’s a compiled language. At this point, I’m also interested in seeing if I can adapt MIJ to run on embedded devices such as the Raspberry Pi Pico I recently got for my birthday.
Will you be taking the challenge to learn Rust next? Let me know!
2021-05-03
![]()
Back to Linux blog.
Book Musings - Star Wars: The High Republic

Happy Revenge of the Fifth! Hope you had a good May the Fourth as well. :-) To kick off my new “Book Musings” blog series where I talk about technical books I’ve read, I figured it’d be fun to start with a Star Wars book. Believe it or not, there is a chapter that I found relatable to my line of work in the technology field:
A Star Wars hacker (systems administrator) is tasked to run simulations to predict the future based on existing data (machine learning). They get an incredibly huge amount of droids connected to each other (a cloud computing cluster) to crunch through the data. The droids (servers) start to overheat once the prediction algorithm starts. To help, the Jedi (senior systems engineers) help out by creating rain (a water cooling solution). In the end, the hacker is able to predict the future accurately and help save the day!
As for the book itself, it’s not my favorite. There are too many stories going on at once and it jumps around randomly. You never get enough time to fully care about the characters or specific stories. I pushed through reading it only to understand this new era of the Star Wars universe (400 years before the Skywalker saga). Here’s to hoping the other book in the series are better!
On a personal level, one of my life goals is to publish a book. If you’ve ever seen my Root Pages notes, you’d know that I’m passionate about technical writing. As a stretch goal, I’d love to write a Star Wars book. Timothy Zahn was a huge inspiration for me getting into reading recreational books. I’d love to be able to write some books that complement his work. I also understand and relate to how hard it is to write a book so props to all of the authors out there!
Book musings on real technical books are coming. Stay tuned! - Luke Short
2020-12-18
![]()
Back to Linux blog.
Why I Ditched CentOS for Debian

Earlier this year, even before CentOS 8 shortened its life to transition to Stream, I moved all of my servers off of CentOS and switched to Debian. Let me explain why.
Disclaimer: Even though I work(ed) for Red Hat, I was never involved with the RHEL team nor do I have any information on the direction of the product or the CentOS project.
- Arm support. This came too little, too late. It took almost an entire year after CentOS 8 came out for an Arm image to be provided. Debian currently has support for 9 different CPU arhitectures, incluing Arm. For a long time, I painstakingly was the only maintainer of a (hacky) build of CentOS 8 and Fedora for the Rock64 and Pine64 devices. It was not worth the time investment as I rather spend time on other projects and studying new technologies. I also ditched the Rock64 devices for the Raspberry Pi. You will get no better software and hardware support than with the original single-board computer that started all of the “clone wars.”
- Kubernetes support. The release of Enterprise Linux (EL) 8 completely removed the legacy iptables package in favor of pushing for nftables usage instead. This has caused many headaches for me as most software out there, including Kubernetes, relied on it. I did a lot of research in the past and found that the Linux kernel it ships still has the necessary patches for legacy iptables to work. There’s simply no
iptables-legacy package/binary to install. Kubernetes support is still limited to RHEL/CentOS 7 right now. Heck, even the open source version of OpenShift (OKD) did not work on EL 8 until a few months ago! Other Kubernetes distributions, such as k3s, have limited support on EL 8 which (1) requires that there’s no firewall enabled and (2) kube-proxy will not work properly.
- Btrfs support. RHEL 7, and by extension CentOS 7, has deprecated the Btrfs file system and removed it from EL 8. This is my favorite go-to free and open-source software (FOSS) Linux file system. I heavily use the snapshot functionality to take quick and easy backups. Red Hat simply has no Btrfs engineers so I understand why they made the move. Hopefully, now that Fedora supports Btrfs by default, things may change in the future.
- Upgrade path. CentOS has no upgrade path. No official one, anyways. Users have reported mixed results of going from CentOS 7 to 8 by simply updating the repository URLs. Only RHEL has an upgrade path and I do not use that distribution except for work purposes (i.e., not my personal projects).
- Licensing. Take this with a grain of salt as I have no supporting evidence for this. I have heard from a few different colleagues from different companies that if you modify CentOS or run Ubuntu at a large-scale then either Red Hat (CentOS) or Canonical (Ubuntu) will go after you seeking licensing compensation. Although Debian is backed by Canonical, it’s a truly a FOSS operating system with no strings attached. I also do not use RHEL itself because I do not want to deal with subscriptions.
- Compatibility. Here’s a fun fact that many people don’t know: CentOS != RHEL. What I mean is that it’s common for packages to be different. The biggest headace I ran into was in the OpenStack community. We had a hell of a time trying to use CentOS 8.0. It was based on an old beta of RHEL 8.0 while RHEL 8.0 continued to get major package updates. More specifically, the Container Tools Podman package (Red Hat’s replacement for the Docker Engine) was stuck at an older version in CentOS and was updated at the last minute in RHEL before the release. CentOS did NOT resync with RHEL again until the 8.1 release. We had to write a lot of workaround patches.
if CentOS: apply_stupid_and_complex_fix(). Debian is Debian. No ifs, ands, or buts. I’ll leave this point with a question for you to ponder: is software that’s older more stable or is newer more stable?
- Toy Story. This wasn’t really a deciding factor, just some fun trivia. Each Debian release name is based on a Toy Story character. In fact, even the logo is literally the chin of Buzz Lightyear! Toy Story’s one of my favorite Disney movies and Debian Wheezy was the first release of Debian I ever tried so it has a special place in my heart. Back when my girlfriend (now wife) and I were celebrating an anniversary at Disney World, we found a Wheezy stuffed animal. I had to have him and my girlfriend graciously bought him for me. He’s been with me ever since. :-)
What do you think? Am I justified in leaving CentOS? I have no regrets so far!
2020-12-14
![]()
Back to Linux blog.
3 FREE Drop-in Replacements for RHEL and CentOS 8
Wow. Out of nowhere, CentOS 8 just annouced it’ll be going end-of-life next year. It was supposed to recieve updates until the year 2029.
Here are three alternatives to checkout. Oracle Linux is the only one you can download and use today. The others are a work-in-progress. All of these can be used as a drop-in replacement. A simple change of the repository URLs should be all that’s required to switch to one of these.
- CloudLinux OS = CloudLinux brings its years of experience and infrastructure to help create a CentOS 8 replacement.
- Rocky Linux = Created by one of the original founders of CentOS.
- Oracle Linux = A free alternative to RHEL that provides additional features including the “Unbreakable Linux” kernel.
CentOS as a project is not ending. CentOS 7 will continue to get full support until 2024. CentOS Stream is being pitched as the official replacement to CentOS 8. This more-so aligns with how Red Hat handles their open source projects: there is a leading-edge open-source technology that gets polished and turned into a product. This means that CentOS Stream will be an unstable project since it has the latest (barely tested) changes. I speak from experience that there’s a HUGE difference between a stable CentOS 8.Y point release and a rolling release. I will elaborate on this in a follow-up blog.
I can no longer recommend it as a production operating system to use. Can/should you use CentOS Stream for CI/CD for a product that’s being deployed on RHEL? Sure, tack it on as another distro. Make sure you also use Oracle Linux or another alternative to test the stable point releases, though, if you cannot use RHEL itself due to licensing/financial constraints. RHEL 8 also provides free-to-use container images via the Universal Base Images (UBIs). CentOS Stream will still, at least, more closely align with RHEL than Fedora does.
Good luck with the migrations! R.I.P. CentOS.
2020-12-10
![]()
Back to Linux blog.
Benchmarking OpenZFS 2.0
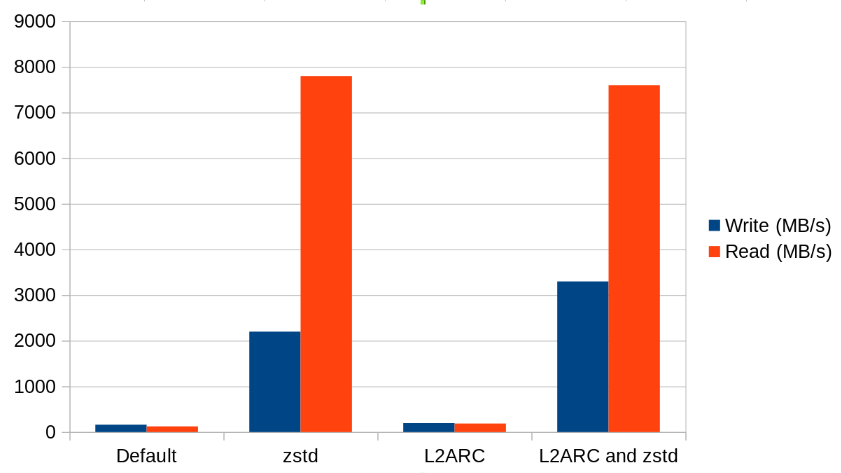
My OpenZFS benchmarks are in and the results are very enlightening!
The graph focuses on the tests using sequential zero read and writes. These seem to be more accurate than the urandom tests.
Let me cut to the chase:
- The new zstd compression in OpenZFS 2.0 is awesome. The results speak for themselves. I highly recommend enabling that.
- L2ARC cache is also a very compelling feature to use. From what I have seen from other benchmarks online, ZFS handles caching storage from a slower drive to a faster drive better than other file systems (such as Bcachefs).
Here are the full results for reference:
| L2ARC |
Zstandard (zstd) Compression |
Local or CIFS |
/dev/zero or /dev/urandom |
Write (MB/s) |
Read (MB/s) |
| No |
No |
Local |
zero |
161 |
124 |
| No |
No |
Local |
urandom |
60.6 |
172 |
| No |
Yes |
Local |
zero |
2200 |
7800 |
| No |
Yes |
Local |
urandom |
60.9 |
171 |
| Yes |
No |
Local |
zero |
196 |
187 |
| Yes |
No |
Local |
urandom |
60.7 |
171 |
| Yes |
Yes |
Local |
zero |
3300 |
7600 |
| Yes |
Yes |
Local |
urandom |
61.0 |
172 |
| No |
No |
CIFS |
zero |
138 |
188 |
| No |
No |
CIFS |
urandom |
60.0 |
178 |
| No |
Yes |
CIFS |
zero |
1700 |
250 |
| No |
Yes |
CIFS |
urandom |
59.0 |
2100 |
| Yes |
No |
CIFS |
zero |
128 |
60.0 |
| Yes |
No |
CIFS |
urandom |
60.1 |
175 |
| Yes |
Yes |
CIFS |
zero |
1500 |
2500 |
| Yes |
Yes |
CIFS |
urandom |
60.0 |
174 |
Considerations for future benchmarking of OpenZFS:
- The virtual machine used for testing may be missing an optimization for /dev/urandom generation. Across the board, the write speeds from /dev/urandom were at 60 MB/s. All of those write tests can be assumed invalid for now. I may revisit this in the future.
- CIFS always exagerates its speeds. I’m unsure how to overcome this. It’s likely to be a mount option or two.
- CIFS should be tested as a mount on an external machine.
- L2ARC cache tests were not conclusive enough. For future tests,
arcstat and arcsummary should be used to monitor caching. Using a large set of files may help as well.
Test Setup
Virtual machine specs:
- Hypervisor: KVM
- Debian 10.7
- 8 vCPUs (4 cores, 8 threads) provided by an AMD Ryzen 3950X
- 32 GB DDR4 RAM 3200 MHz
- Storage:
- SSD 80 GB passthrough
- Speed rated at 500 MB/s (read and write
- HDD 8 TB passthrough
- Speed rated at 185 MB/s (read and write)
- Settings:
- Cache mode = none
- IO mode = native
- Network = VirtIO bridge
ZFS pool created on my 8 TB HDD:
$ sudo zpool create zfsbenchmark sdb
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 74.5G 0 disk
sdb 8:16 0 7.3T 0 disk
├─sdb1 8:17 0 7.3T 0 part
└─sdb9 8:25 0 8M 0 part
vda 254:0 0 80G 0 disk
└─vda1 254:1 0 80G 0 part /
Zstandard compression setup on a different dataset:
$ sudo zfs create -o casesensitivity=mixed -o compression=zstd zfsbenchmark/zstd
CIFS setup:
$ sudo apt install samba cifs-utils
$ sudo zfs set sharesmb=on zfsbenchmark
$ sudo useradd zfoo
$ sudo smbpasswd -a zfoo
New SMB password: bar
Retype new SMB password: bar
Added user zfoo.
$ sudo mkdir /cifs/
$ sudo chown -R zfoo /cifs
$ sudo mount -t cifs -o username=zfoo,password=bar //127.0.0.1/zfsbenchmark /cifs/
$ sudo su - zfoo
Add a SSD as a cache front of the HDD. This is also known as a L2ARC cache. This was only done after all of the non-L2ARC benchmarks were completed:
$ sudo zpool add zfsbenchmark cache sda
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 74.5G 0 disk
├─sda1 8:1 0 74.5G 0 part
└─sda9 8:9 0 8M 0 part
sdb 8:16 0 7.3T 0 disk
├─sdb1 8:17 0 7.3T 0 part
└─sdb9 8:25 0 8M 0 part
vda 254:0 0 80G 0 disk
└─vda1 254:1 0 80G 0 part /
How were the benchmarks performed? Before every test, I ran sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_caches to sync all writes to the disk and flush out the swap. The tests were preformed using similar commands to write and read 10 GB files:
# Zero
## Write
$ sudo dd if=/dev/zero of=/zfsbenchmark/zero.img bs=1M count=10000
$ sudo dd if=/dev/zero of=/zfsbenchmark/zstd/zero.img bs=1M count=10000
$ sudo dd if=/dev/zero of=/cifs/zero.img bs=1M count=10000
## Read
$ sudo dd if=/zfsbenchmark/zero.img of=/dev/null bs=1M
$ sudo dd if=/zfsbenchmark/zstd/zero.img of=/dev/null bs=1M
$ sudo dd if=/cifs/zero.img of=/dev/null bs=1M
# Random
$ sudo dd if=/dev/urandom of=/zfsbenchmark/nonzero.img bs=1M count=10000
$ sudo dd if=/dev/urandom of=/zfsbenchmark/zstd/nonzero.img bs=1M count=10000
$ sudo dd if=/dev/urandom of=/cifs/nonzero.img bs=1M count=10000
## Read
$ sudo dd if=/zfsbenchmark/nonzero.img of=/dev/null bs=1M
$ sudo dd if=/zfsbenchmark/zstd/nonzero.img of=/dev/null bs=1M
$ sudo dd if=/cifs/nonzero.img of=/dev/null bs=1M
Side note: /dev/urandom is NOT secure. I only used it for testing because, in theory, it’s supposed to be faster. Stick to /dev/random for generating random entropy for use in production applications.
So long for now!
2020-12-06
![]()
Back to Linux blog.
Taking OpenZFS 2.0 out for a Spin!

OpenZFS 2 has arrived! The open source project for providing the ZFS file system on BSD, Linux, Windows, and (soon-to-be) macOS had a major release this past week.
I’m a huge fan of Btrfs (or Buttery-F-S, as I like to call it). For the longest time, Btrfs was the king of Linux file systems. Some may say that it’s unstable because companies like Red Hat have removed support for it. However, Red Hat has 0 engineers working on the project. On the other hand, SUSE has a full department that works diligently on this wonderful file system. Once upon a time, it was not stable. I have experienced many file systems corruptions with Btrfs back in the day when it was young. Things have changed and nowadays it’s a real contender for production workloads. Where does ZFS fit into all of this? Well, it could be argued that Btrfs has spent its entire life trying to catch up with ZFS in terms of features and performance.
In a world where patents and licesning do not matter, ZFS takes the crown. It’s literally the perfect file system that includes everything plus the kitchen sink! Copy-on-write, datasets/subvolumes, compression, snapshots, live/hot FSCK, RAM cache, cache drives, data deduplication, software RAID support, and more!
I was excited to hear when OpenZFS 2.0 was released but, at the same time, confused at the lack of packaging. I have been waiting a long time for this release, so let’s dive right into the source now and build it from scratch! These are my notes on how to build and install OpenZFS 2.
To test this, I created a Debian 10 virtual machine with two additional QCOW2 images attached. Imagine, if you will, that /dev/vdb is our SSD and that /dev/vdc is our HDD. The SSD will be used as a cache drive for the HDD. This is a trial of how I will end up re-configuring my home file server using Debian and ZFS.
ZFS Pool Creation
These are my existing partitons:
$ sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 254:0 0 80G 0 disk
└─vda1 254:1 0 80G 0 part /
vdb 254:16 0 1G 0 disk
vdc 254:32 0 10G 0 disk
Create the main pool using the HDD:
$ sudo zpool create examplepool vdc
Add the SSD as a L2ARC (cache) drive:
$ sudo zpool add examplepool cache vdb
Here are our partitions now:
$ sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 254:0 0 80G 0 disk
└─vda1 254:1 0 80G 0 part /
vdb 254:16 0 1G 0 disk
├─vdb1 254:17 0 1014M 0 part
└─vdb9 254:25 0 8M 0 part
vdc 254:32 0 10G 0 disk
├─vdc1 254:33 0 10G 0 part
└─vdc9 254:41 0 8M 0 part
Let’s examine the status of the pool:
$ sudo zpool status
pool: examplepool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
examplepool ONLINE 0 0 0
vdc ONLINE 0 0 0
cache
vdb ONLINE 0 0 0
errors: No known data errors
Dataset Creation
Create a dataset (similar in concept to Btrfs subvolumes). Let’s also set case insensitive so this will work as a CIFS share on Windows along with the newly anticipated zstd compression:
$ sudo zfs create -o casesensitivity=mixed -o compression=zstd examplepool/exampledataset
Check out the new dataset. Notice how pools and datasets will automatically mount themselves:
$ sudo zfs list
NAME USED AVAIL REFER MOUNTPOINT
examplepool 178K 9.20G 24K /examplepool
examplepool/exampledataset 24K 9.20G 24K /examplepool/exampledataset
Compression
How do we know if compression is working? Let’s create a large file full of zeroes:
$ sudo dd if=/dev/zero of=/examplepool/exampledataset/zero.img bs=1M count=100
Notice how zstd compresses that 100MB file down to basically nothing! Granted, it’s easy to compress an endless supply of zeroes. You won’t be able to get infinite storage by using compression. ;-)
$ sudo zfs list
NAME USED AVAIL REFER MOUNTPOINT
examplepool 189K 9.20G 24K /examplepool
examplepool/exampledataset 24K 9.20G 24K /examplepool/exampledataset
How about a test with a more “real life” example. Let’s create another 100 MB file but this time it will be full of random data:
$ sudo dd if=/dev/urandom of=/examplepool/exampledataset/nonzero.img bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 2.35945 s, 44.4 MB/s
Seeing is believing! We have saved 7 MB of space thanks to compression. The space savings will vary upon each individual file/inode:
$ sudo zfs list
NAME USED AVAIL REFER MOUNTPOINT
examplepool 93.2M 9.11G 24K /examplepool
examplepool/exampledataset 93.1M 9.11G 93.1M /examplepool/exampledataset
Samba/CIFS
Samba time! Cue catchy dance music. ZFS supports settings up NFS and Samba shares. Let’s try Samba since it’s a bit more complex:
$ sudo apt install samba
$ sudo zfs set sharesmb=on examplepool/exampledataset
$ sudo useradd foo
$ sudo chown -R foo.foo /examplepool/exampledataset/
$ sudo smbpasswd -a foo
New SMB password: foobar
Retype new SMB password: foobar
Added user foo.
Let’s verify the CIFS mount works properly:
$ sudo apt install cifs-utils
$ sudo mount -t cifs -o username=foo,password=foobar //127.0.0.1/examplepool_exampledataset /mnt
$ ls -lah /mnt
total 103M
drwxr-xr-x 2 root root 0 Dec 4 06:54 .
drwxr-xr-x 19 root root 4.0K Dec 4 06:38 ..
-rwxr-xr-x 1 root root 100M Dec 4 06:54 nonzero.img
-rwxr-xr-x 1 root root 100M Dec 4 06:51 zero.img
Closing Remarks
Pools, datasets, compression, CIFS with ZFS, and ZFS on Linux: it’s true. All of it. It works on Linux! Don’t take my word for it, go try it for yourself! :-)
Stay tuned for a future article on ZFS performance tuning and benchmarking!
2020-11-29
![]()
Back to Linux blog.
Using a DSLR as a Webcam on Linux

Ever wonder how to setup a DSLR to use as a high-end webcam in Linux? Me too.
I had a spare camera that I used to use all the time. That is, until my wife got a Google Pixel phone. It has been collecting dust for years - until now! I have been inspired by my peers and even my wife who are striving for that ultra-professional look during work calls. Using a DSLR really takes your video call to the next level.
For Windows users, it is almost a plug-and-play experience with Canon, Nikon, and Sony now having software to convert their DSLRs into webcams. Some vendors support macOS but good luck finding any support for Linux users! Add this to the list of “things you need to get your hands dirty with to have it work with Linux.” Although, I am proud to say that that list is ever shrinking! Year of the Linux desktop coming, anyone?
This tutorial focuses on Arch Linux and should also apply to Ubuntu and openSUSE. For Fedora users, you need to compile the obs-v4l2sink from source using a workaround patch or wait until OBS Studio 26.1 gets fully released in the coming days/weeks.
My full guide on setting up a DSLR for use in video conferencing can be found in my technical notes here.
P.S. - Pro tip for glasses wearers from my buddy Kevin Carter: get a polarizing filter to help reduce the amount of glare from the computer screen on your glasses. Also try changing the position of your glasses, rearranging lights, wearing contacts, or just go get LASIK surgery. ;-)
2020-11-26
![]()
Back to Linux blog.
Reaching Over 1,000 Commits On Root Pages!
Over four years ago, I started one of my biggest open source projects ever: my notes.
This is not your typical git project.
It is not some fancy cloud-native application with an API.
This is Root Pages.
At any given time, I like to say that 70% of my technical knowledge is retained within those notes and the GitHub issues page.
It was a spiritual successor to my proprietary notes (dubbed “The Jedi Knight Archive”).
The goal is simple: I want to share everything I learn with others.
This week I passed over the one thousand commit mark!
It is now officially the largest project I have ever created.
Let’s take a walk down the git history lane to see what I have taken the most notes on.
$ git log | grep -o -P '\[.+\]\[+.+\]+' | sort | uniq -c | sort -rn | head -n 20
86 [openstack][tripleo]
39 [virtualization][kubernetes]
30 [virtualization][openstack]
24 [commands][virtualization]
23 [automation][ansible]
23 [administration][chromebook]
19 [programming][go]
15 [virtualization][kubernetes_administration]
14 [programming][devops]
13 [openstack][developer]
13 [computer_hardware][monitors]
13 [commands][package_managers]
12 [virtualization][containers]
10 [administration][operating_systems]
8 [commands][openstack]
7 [virtualization][virtual_machines]
7 [virtualization][kubernetes_development]
7 [linux_commands][virtualization]
7 [administration][graphics]
6 [virtualization][wine]
Looking at the top 20 commits here, we get an idea of what the majority of my notes are. Due to constant restructuring of the pages and not always using these [tags] in my commit messages, this is not completely accurate. It is still fair to say that I spend most of my time working on and learning about OpenStack, Kubernetes, and programming.
- OpenStack = 86 [openstack][tripleo] + 30 [virtualization][openstack] + 13 [openstack][developer] + 8 [commands][openstack] = 137
- Kubernetes = 39 [virtualization][kubernetes] + 15 [virtualization][kubernetes_administration] + 7 [virtualization][kubernetes_development] = 61
- Programming = 19 [programming][go] + 14 [programming][devops] = 33
Searching the whole git history reveals a more accurate number of my notes with programming taking the lead over Kubernetes. That makes sense as I have been programming for over 6 years. Kubernetes has only been a large part of my life for 3. OpenStack has been one of my primary job responsibilities for the past 5 years so there are a lot of ins and outs I have discovered.
$ git log | grep '\[' | grep -P "kolla|openstack|tripleo" | wc -l
233
$ git log | grep '\[' | grep -P "c\+\+|devops|go|packaging|programming|python" | wc -l
103
$ git log | grep '\[' | grep -P "containers|kubernetes" | wc -l
87
Are you curious to learn more about the cloud and technology industry? Feel free to check out my notes, fork them, open GitHub issues, or whatever your heart desires! You can check them out here. My notes are published online at the end of every quarter.
By the way, the day I’m publishing this is Thanksgiving! I’m thankful for the continued support of my friends, family, and colleagues. It’s their motivation and drive that helps to spark my own fire.
I’m now off to eat some Tofurkey (trust me, if you cook anything right and use the correct seasonings it will be delicious)! Cheers!
